CS50 is a first year university course offered by Harvard University and more recently, Yale University, which dives into the basics of computer science, exploring algorithmic thinking and teaching students how to code in a variety of languages including Scratch, C, and Python, amongst others. In the last few weeks of the course, it offers a choice of three tracks - game, web, or mobile development that students can explore and create their final project which is encouraged to be something which is useful beyond the course.
The online course which is known as CS50x offers a stripped down experience of the real course. The assignments, known as problem sets (or psets), are marked against certain criteria and a number of test cases by an automated program. All of your coursework is pushed into individual branches of your own CS50 GitHub repository. I’ve copied these branches into a single repository for ease of perusal, which can be found here.
Week 2
This week’s first problem was called Readability for which the goal was to implement the Coleman-Liau readability index. This algorithm takes into consideration the number of letters per word and words per sentence to calculate a (US) recommended grade for reading.
To implement this, first I request the string off the user - the problem makes a lot of assumptions about the formatting of the text such as there being no repeated spaces, no leading or trailing spaces, and full stops denoting the ends of sentences. Once the string is inputted, the program loops over the character array, calling a function containing a switch statement that checks for either a letter (increment letter count), a space (increment word count), or a full stop, question, or exclamation mark (increment sentence count).
Once this loop is done, it can run the calculation (0.0588 * letter / word * 100 - 0.296 * sentence / word * 100 - 15.8) over the counts and determine the reading level.
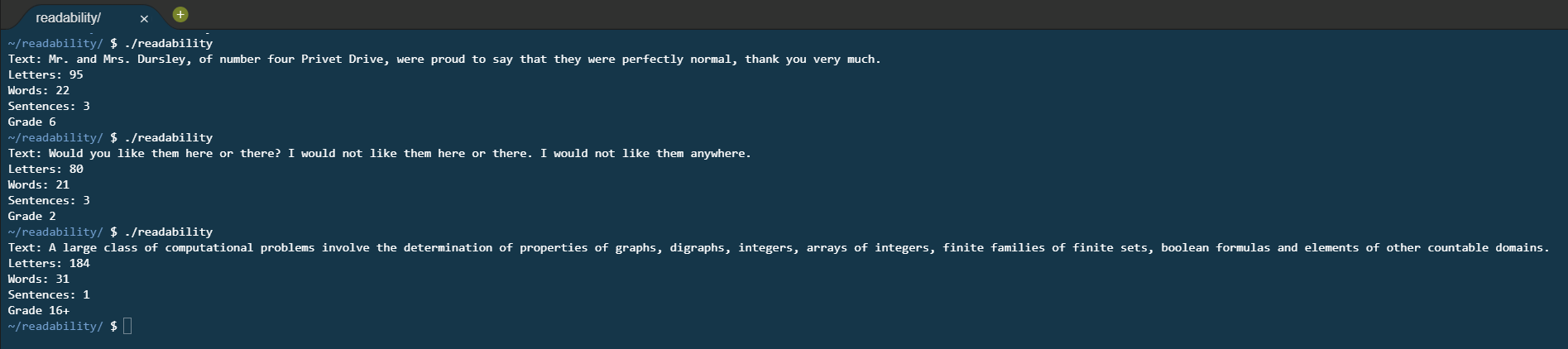
Readability in Action
The “less comfortable” problem was to implement the Caesar cipher, which takes a numeric command line argument and shifts the letters in the plaintext by that number of places so that shifting A by two places would give you C and so forth. This one was kind of challenging because C takes command line arguments as an array of strings, which means getting a numeric value is a little annoying, particularly as one of the requirements of the problem is to handle an input of 20x, which means that using atoi() is out because it ignores any alphabetical components.
Instead, after some discussion with my partner, I implemented what atoi() is basically doing under the hood - that is, looping over each letter of the input, testing if the input is between ASCII 0 and ASCII 9. Then, it multiplies the current key by 10 and adding the number converted to an integer (variable minus 48).
Next, the program prompts the user for input and loops over the plaintext string, taking modulo 26 of the key to create the offset. It then checks if adding the key will be greater than z/Z and loops back around to a/A. This helps preserve the capitalisation and stops really big numbers doing weird stuff.
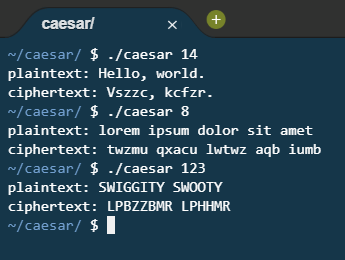
Caesar in Action
Finally, the last problem (more comfortable) of the set was called Substitution, which was actually pretty similar to Caesar in a lot of ways. The key difference is that this program takes a command line argument in the form of a 26 character string which uses each letter of the alphabet exactly once in order to substitute letters based on their position in the alphabet.
First, the program checks if the command line argument is exactly 26 characters long. If it’s not, there’s no point continuing so it bails out. If it is, it then loops over the string, assigning each letter of the command line argument to a key array. Nested within that loop is another loop that iterates through a character array called alphabet with the letters A through Z, against the toupper() of the command line argument character. If the letter is found, it is changed in the alphabet array to something that will never be matched, increments a counter, and continues. If the counter at the end of these loops is not 26, then there are either duplicates or non-alphabetical characters within the command line string.
Originally, my solution to validating that the entire alphabet was present in the string was to add up all the values of A-Z and use that number to validate that there were no duplicates or letters missing from the key, however once I checked my work against the test cases, it became clear that there was an overlapping issue where you could make up this number without having A-Z there and so the above solution was my second attempt (which works much better).
Once the key is validated, it then prompts the user for plaintext and the main logic of the program constructs a ciphertext using the plaintext’s contents minus a/A to find the array index for the letter we want to compare. The ciphertext is then constructed by using the toupper() or tolower() (depending on the plaintext letter it is inspecting) of the key to the index previously created.
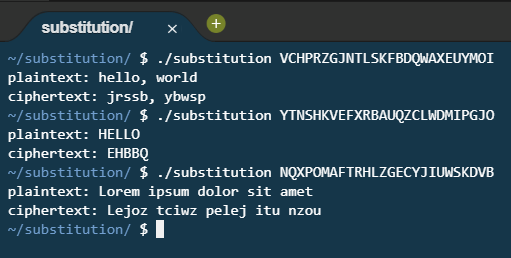
Substitution in Action
At the end of the third week now, and I’m actually starting to feel like this is helpful. I still don’t like C very much but it is forcing me to approach things in a way that I would just use a built-in function for in modern languages. It definitely feels like this is helping me think in a more logical, algorithmic way rather than the intuitive problem solving I usually rely on. I know once I practice this enough for those intuitive methods to work better, then I will start excelling.